What does it do?
On this page:
Display objects visually
Instead of displaying objects as text, we can display them visually. A session in a typical (textual) Python console might looks like this:
>>> url "http://www.pythonanywhere.com" >>> images [BufferedImage@690247: type = 5 ColorModel: #pixelBits = 24 numComponents = 3 co lor space = java.awt.color.ICC_ColorSpace@14a97b transparency = 1 has alpha = fa lse isAlphaPre = false ByteInterleavedRaster: width = 400 height = 300 #numDataE lements 3 dataOff[0] = 2, BufferedImage@82e4f3: type = 5 ColorModel: #pixelBits = 24 numComponents = 3 color space = java.awt.color.ICC_ColorSpace@14a97b transp arency = 1 has alpha = false isAlphaPre = false ByteInterleavedRaster: width = 4 00 height = 300 #numDataElements 3 dataOff[0] = 2, BufferedImage@1852a81: type = 5 ColorModel: #pixelBits = 24 numComponents = 3 color space = java.awt.color.IC C_ColorSpace@14a97b transparency = 1 has alpha = false isAlphaPre = false ByteIn terleavedRaster: width = 400 height = 300 #numDataElements 3 dataOff[0] = 2] >>> tree Div(Add(Load(b), Call(sqrt: Sub(Pow(Load(b), Value(2)), Mul(Mul(Value(4), Load(a )), Load(c))))), Mul(Value(2), Load(a)))
In the Larch Python console, it looks like this:

Larch lets objects can define a visual representation by implementing a method called __present__. It's a lot like the __str__ and __repr__ that represent an object as text. This is how the tree nodes were able to define a visual representation that combined their nested structure with a form similar to that of a mathematical expression.
Visual representations can be interactive too. In the image below, a virtual machine object is created in a console. Its visual representation displays its state, along with GUI controls that can be used to step through the assembly code that it executes:
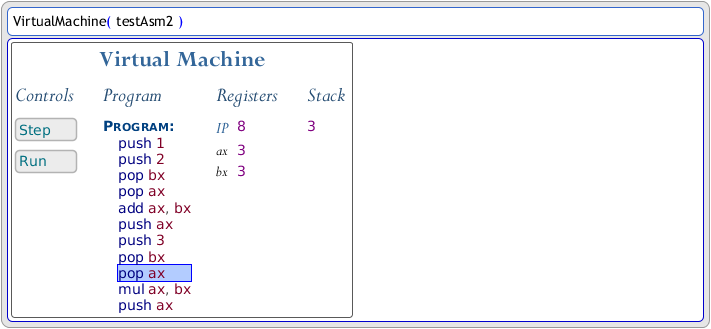
Partially visual programming
Visual programming languages have a rich history in the research community. Unfortunately, developers have never really taken to them, as they don't scale well (diagrammatic representations of fibonacci are fine, while larger programs look like giant rats nests), and programming with a mouse is slow and cumbersome. As a consequence, plain text has remained the dominant medium for source code.
Why would we want to try something other than plain text when it works so well? Take a look at any scientific or technical text book. While it is mostly text, it employs diagrams, tables, spatial layout and other visual forms where plain text would not convey the desired information effectively. Programmers cannot do this within their source code and miss out as a result. Larch addresses this problem by allowing you to use interactive, visual forms within your (textual) source code, where they are beneficial.
Visual programming constructs are implemented as objects that are embedded within source code. The object defines a visual representation that displays the desired UI, that is rendered in-line within the code.
Some things need to be visual
Lets consider a simple example. In the code below, the function convex computes the convex hull (see Wikipedia entry) of a polygon.
convex(Polygon([Point2(-25.0, -25.0), Point2(25.0, -25.0), Point2(25.0, 25.0),
Point2(-25.0, 25.0), Point2(-51.0, 19.0), Point2(-20.0, 16.0),
Point2(-4.0, 15.0), Point2(8.0, 8.0), Point2(11.0, -5.0)]))
If you want to see what shape the polygon is, you will probably need to get a piece of graph paper at plot the co-ordinates. Within Larch, we just embed the polygon within the source code:
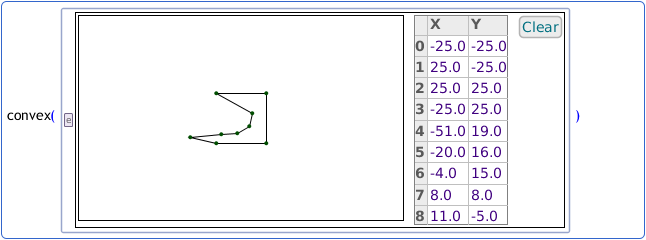
The polygon can be modified in-place; you can draw new vertices or edit the co-ordinates in the table on the right.
We can fix regular expressions
Regular expressions are a useful tool. Many programmers would say that they aren't broken in the first place. They can however be difficult to read. A complex regular expression compounded with frequent use of escape sequences to match control characters can take a while to de-tangle for all but the most experienced programmers. Their tricky notation is the inspiration for Blackwell's SWYN. Larch has a visual regular expression editor that leaves their textual syntax intact, while using visual cues and spatial layout to guide the eye:
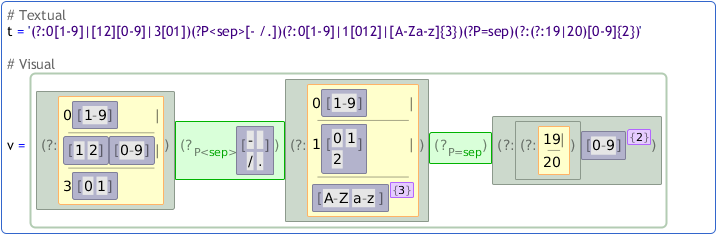
The visual regular expressions can be edited in-line; Larch reckognises regex constructs and applies visual cues as-you-type. You can also cut-and-paste to and from external text editors, making our regex editor a potentially useful tool its own right, even if you don't want to use Larch to do any real programming.
Visualisation techniques are useful whenever you are dealing with data whose textual notation is difficult to follow.
Code that looks like technical literature
Well written technical literature elegantly communicates a problem and a solution in a way that is easy to understand. When we turn this into code, a lot of the elegance is lost, as our programming languages force us to translate the ideas and concepts into a form that a compiler can handle. The source code is often more verbose, as it interweaves the original ideas with aspects of the implementation. It is often difficult to see the woods for the trees.
As an example, let us consider a MIPS CPU simulator. It reads in instructions in binary form, and emulates them. The implementation of such as simulator would look something like this:
OPCODE_ADD_REG_REG = 0b000000100000
OPCODE_ADD_REG_IMM = 0b001000000000
OPCODE_DIV_UNSIGNED = 0b000000011011
# A constant for each instruction...
def simulate_instruction(cpu, instruction_word):
opcode = extract_opcode(instruction_word)
if opcode == OPCODE_ADD_REG_REG:
# Extract operands
op0, op1, op2 = extract_operands(instruction_word, OP_REG, OP_REG, OP_REG)
# Simulate effect of instruction
value = cpu.regs[op1] + cpu.regs[op2]
cpu.regs[op0] = value & 0xffffffff
cpu.advance_program_counter()
elif opcode == OPCODE_ADD_REG_IMM:
# Extract operands
op0, op1, op2 = extract_operands(instruction_word, OP_REG, OP_REG, OP_IMM)
# Simulate effect of instruction
value = cpu.regs[op1] + bits_16_to_signed(op2)
cpu.regs[dst] = value & 0xffffffff
cpu.advance_program_counter()
elif opcode == OPCODE_DIV_UNSIGNED:
# Extract operands
op0, op1 = extract_operands(instruction_word, OP_REG, OP_REG)
# Simulate effect of instruction
quotient = cpu.regs[op0] / cpu.regs[op1]
modulus = cpu.regs[op0] % cpu.regs[op01
cpu.lo_reg = quotient
cpu.hi_reg = modulus
cpu.advance_program_counter()
# More elif blocks; one for each instruction...
Other approaches — besides an if-else block — can be used. The implementation of each would be somewhat different. The assembler must also be implemented separately.
We have developed a simplified MIPS simulator that runs within Larch. The source code looks like this:

The instruction set is described in a table that would be familiar to anyone who has read some technical document describing a CPU instruction set, e.g. the Wikipedia entry for MIPS. The instruction set is seen, while the details of the underlying implementation of the simulator are hidden. The table is fully editable; the text in the first 6 columns can be modified, while the code in the 'Sim code' column is displayed using a Python code editor. An instruction can be added by using a spreadsheet style block copy operation to duplicate an existing row that describes a similar instruction, after which it can be modified. The table also contains sufficient information to drive the assembler, as it has the necessary information to describe the syntax of each instruction. Modifying the table changes both the assembler and the simulator at once.The table-based approach also separates the description of the instruction set from the implementation of the simulator, allowing them to be modified independently. The simulator implementation can be modified (e.g. to improve performance) without affecting the instruction set implementation. In contrast, exchanging the if-else block implementation for a different approach in the text-based sorce code seen previously would necessitate changes that affect the instruction set implementation as well.
Interactive table-based unit tests
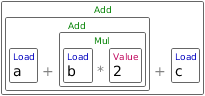
We can use embedded tables to create domain specific unit tests. In this example we consider a parser for simple expressions involving variables, numbers, arithmetic operators and function calls. Basically, we want to parse something like a + b * 2 + c to convert it to AST form (note the visual AST notation, seen previously):
The parser is implemented using the Larch parser library, which allows a grammar to be described as a class, with decorated methods defining the rules. For example:
class SimpleExpressionGrammar (Grammar):
__junk_regex__ = '[ ]*'
decimalInteger = RegEx('(-?[1-9][0-9]*)|0')
@Rule
def value(self):
return self.decimalInteger.action(lambda input, begin, end, xs, bindings: Value(xs))
... more parser rule methods ...
@Rule
def add_sub(self):
return (self.mul_div() + ((Literal('+') | Literal('-')) + \
self.mul_div()).zeroOrMore()).action( \
_leftInfixOpAction({ '+':Add, '-':Sub }))
... more parser rule methods ...
@Rule
def expression(self):
return self.add_sub()
Further down, we would have our unit tests:
class TestSimpleExpressionParser (unittest.TestCase):
def test_value(self):
self.assertEqual(_g.value().parseStringChars('12').getResult(), value('12'))
self.assertFalse(_g.value().parseStringChars('abc').isValid())
... more tests ...
def test_expr(self):
self.assertEqual(_g.expression().parseStringChars('1').getResult(),
Value('1'))
self.assertEqual(_g.expression().parseStringChars('a').getResult(),
Load('a'))
self.assertEqual(_g.expression().parseStringChars('a*b').getResult(),
Mul(Load('a'), Load('b')))
self.assertEqual(_g.expression().parseStringChars(
'a*(b+c)').getResult(), Mul(Load('a'), Add(Load('b'), Load('c'))))
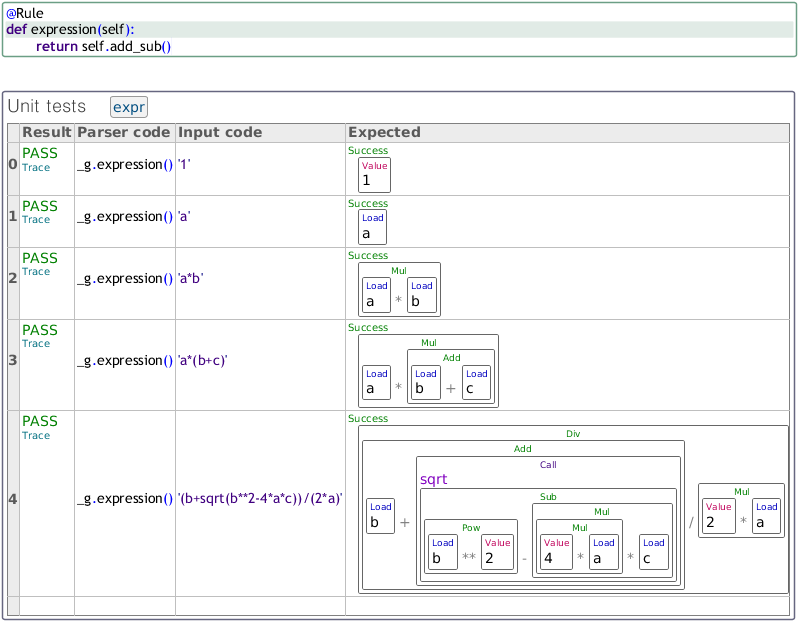
self.assertEqual(_g.expression().parseStringChars(
'(b+sqrt(b**2-4*a*c))/(2*a)').getResult(),
Div(Add(Load('b'), Call('sqrt', [Sub(Pow(Load('b'),
Value('2')), Mul(Mul(Value('4'), Load('a')),
Load('c')))])), Mul(Value('2'), Load('a'))))
You have to be quite careful when reading the last assertion in the test_expr method, as you need to pick apart the nested structure to fully understand what is going on. Also, this kind of assertion is not particularly fun to write, as you have to carefully figure out what you expect your parser to generate (although I gather some programmers would put in a dummy value, let the test fail, copy the output from the console and check it before pasting it in).
Readability could be improved by embedding a visual version of the structure within the assertion. Unfortunately, it would not be editable making modifications cumbersome to perform. Our table-based unit test is shown below:
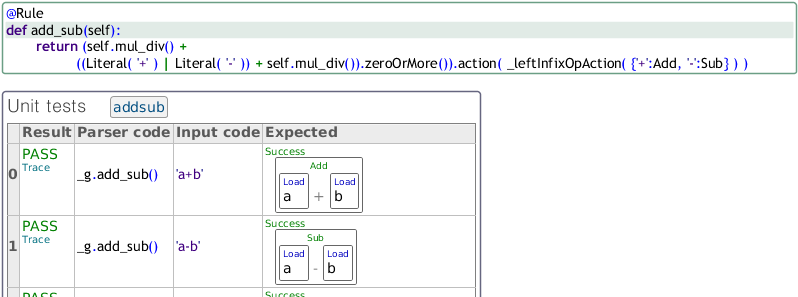
Note that the unit tests are placed just below the code that they test. Typical plain text source code typically separates code and tests, placing them within different parts of the same module or within different modules completely.
Here we see the benefits of table based tests. The parser rule that is tested and the input text are displayed in separate columns. The expected result is presented visually, enhancing the readability of the tests. It is also worth noting that none of the expected results had to be entered by hand. In the next figure we see what happens when a new assertion row is entered. The 'Parser code' and 'Input code' cells are filled in and the module executed:
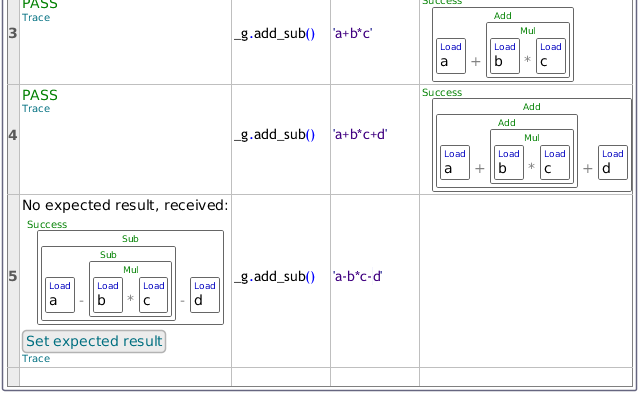
The unit test informs us that it has received a result from executing the test, but has no expected result to compare it to. You can look at the received result and determine that it is indeed correct, at which point you can click the 'Set expected result' button to move it into the 'Expected result' cell. From this point on, this value will be used as the expected result. This can save a lot of typing and tricky programming work.
Inspiration
The inspiration for the development of Larch has come from a variety of sources. It started in 2004 when I read the article Extensible programming for the 21st Century by Gregory V. Wilson. Since then, I have been inspired by a number of projects, such as Barista by Andrew Ko.